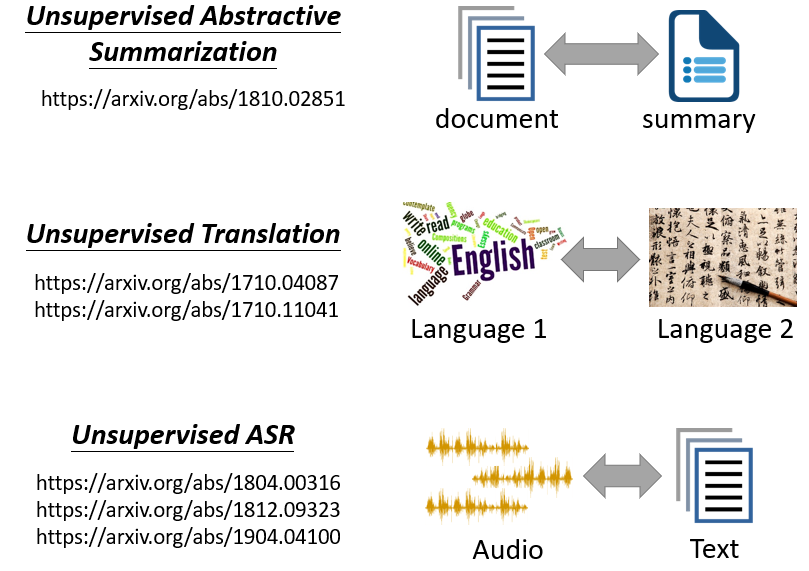
06-Generative Adversarial Network(GAN)
1. 基本概念
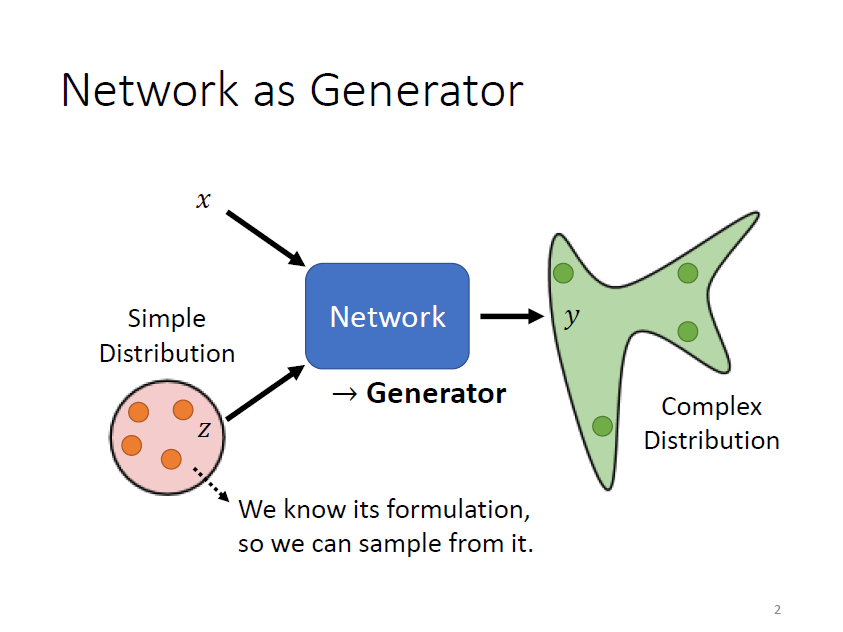
輸入 neural network 的除 以外,還有一個從某一簡單的(已知)分布中隨機採樣得到的一個 random 的 variable,其中這個 neural network 就是 generator
使用的 simple distribution 如:Gaussian distribution、Uniform distribution 等等
方法:
- 兩個向量直接接起來,變成一個比較長的向量作為 network 的 input
- 跟 長度一樣,直接相加以後做為 network 的 input
注意:
從 network 輸出的也將是一個分布
目的是希望模型的輸出是 creative,如繪畫、聊天機器人等等
2. Generative Adversarial Network(GAN)
2.1 Unconditional Generation
不考慮 ,只先單純考慮從 simple distribution 採樣出來的
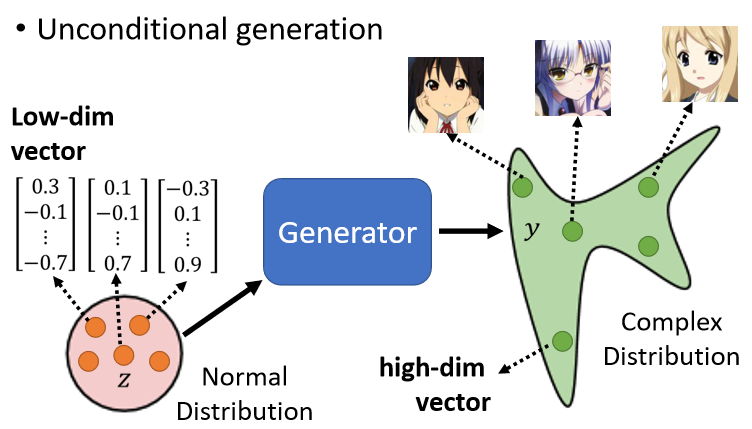
是從一個 normal distribution 裡 sample 出來的向量,通常會是一個 low-dimensional 的向量,而一張圖片就是一個非常高維的向量,所以 generator 實際上做的事情就是產生一個非常高維的向量,當輸入的向量不同(不同的 ),輸出就會跟著改變
注意:
所選擇的不同 z 的 distribution 之間的差異並沒有非常大,但 generator 會想辦法把此簡單的 distribution 對應到一個複雜的 distribution
2.2 Discriminator
discriminator 也是一個 neural network,其中裡面的架構可以自己設計,例如可以使用 CNN、Transformer 等等
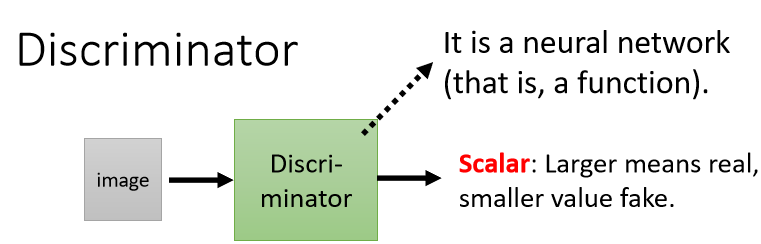
把 generator 的輸出(一個高維向量)輸入到 discriminator,discriminator 會產生一個數字 scalar,越大代表 generator 的輸出越真實越合理
2.3 Algorithm
步驟:
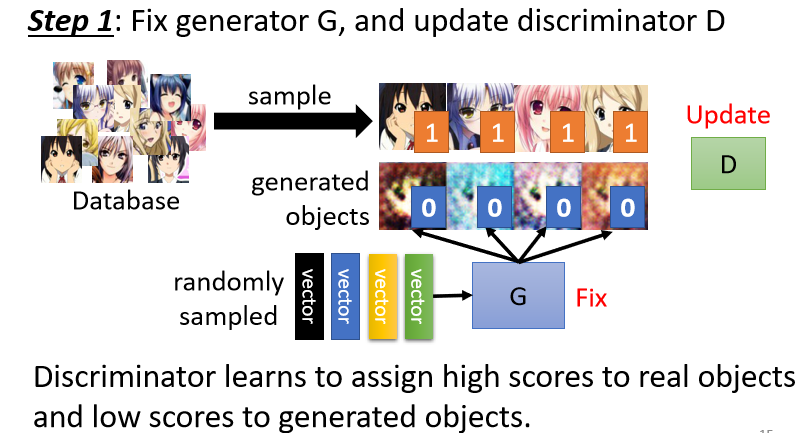
- 初始化 generator 與 discriminator
- 固定 generator G,更新 discriminator D
- 固定 discriminator D,更新 generator G
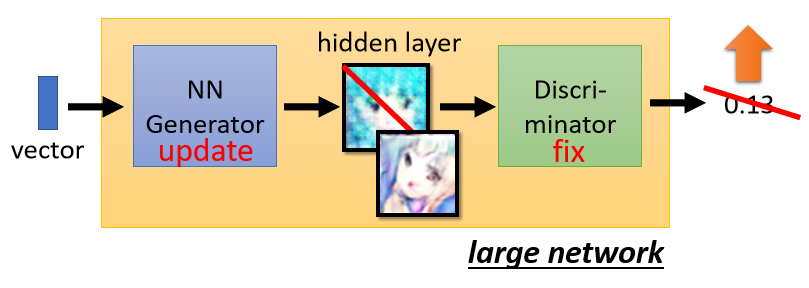
目標是希望 discriminator 產生的 scalar 越高越好
- 重複步驟 2. 和 3.
注意:
- generator 的參數是隨機初始化的,例如從高斯分布中 random sample 一堆 vector 丟到 generator,起初一些圖片會跟正常的二次元人物非常的不像
- 對於 discriminator 來說,這就是一個分類或是回歸問題。需要拿真正的二次元人物頭像跟 generator 產生出來的結果,去訓練 discriminator 來分辨他們的差異
- 若視作分類問題,就把真正的人臉當作類別 1,generator 產生出來的圖片當作類別 2,然後訓練一個 classifier
- 若視作回歸問題,教 discriminator 看到真實二次元人臉圖片輸出 1,看到生成的圖片輸出 0
2.4 實例
2.4.1 Anime Face Generation

2.4.2 Progressive GAN
generator 輸入一個簡單向量,輸出一張高維的向量(圖片)。把輸入的向量做內插 interpolation,可以看到兩張圖片之間連續的變化

2.4.3 The first GAN
Generative Adversarial Networks
2.4.4 BigGAN
Large Scale GAN Training for High Fidelity Natural Image Synthesis
3. Theory behind GAN
有一個 generator,輸入許多從 normal distribution 採樣得到的向量,會輸出一個覆雜的 distribution,稱為 ;而有一堆的真正的 data 也形成了另外一個 distribution,稱為 ,期待 跟 越接近越好
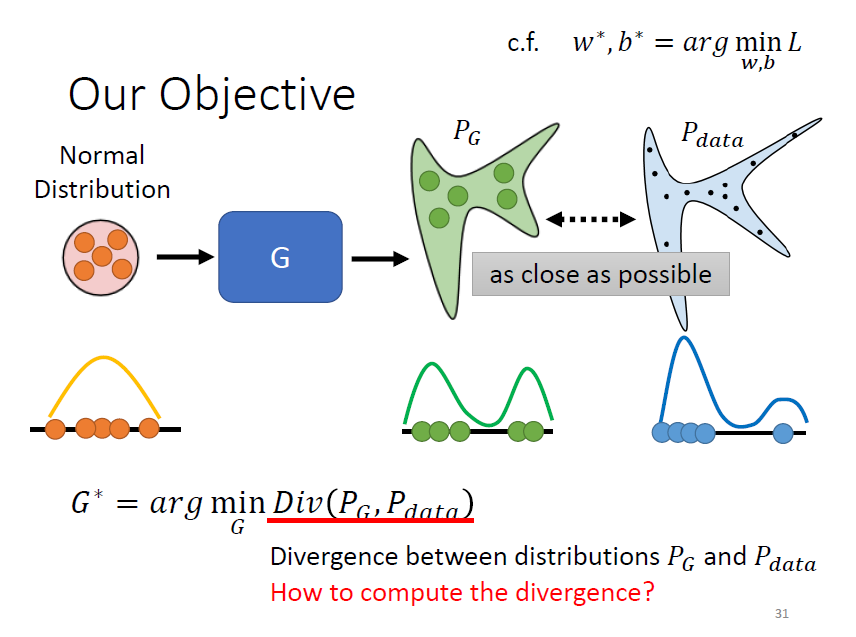
從 和 sample 出一些 data,並借助 discriminator 計算 divergence 衡量 distribution 之間的距離

訓練 discriminator,希望看到 real data 就給比較高的分數,看到 generator 的 data 就給比較低的分數
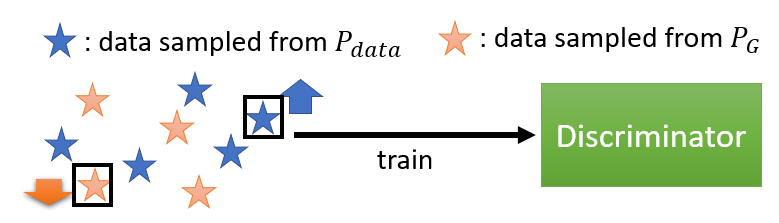
寫成公式:
:從 裡面 sample 出來的 經過 discriminator 得到分數,再取
:從 裡面 sample 出來的 經過 discriminator 得到分數,再取
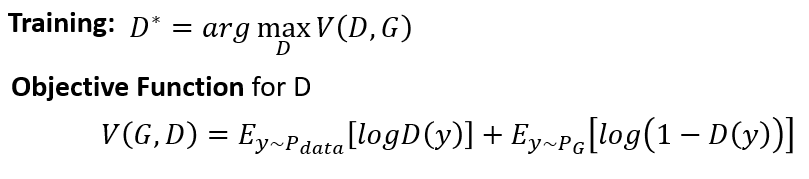
目標:
希望 越高越好,希望 越低越好
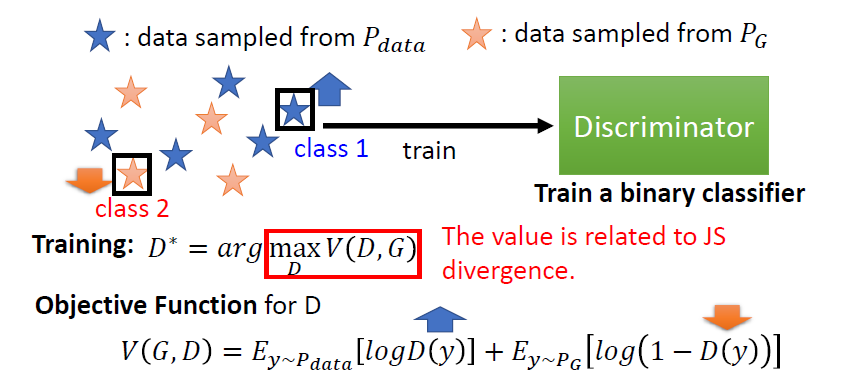
注意:
不一定要把 objective function 寫成這個樣子,它可以有其他的寫法,最早年之所以寫成這個樣子,是為了要把 discriminator 跟 binary classification 扯上關係
直觀理解:
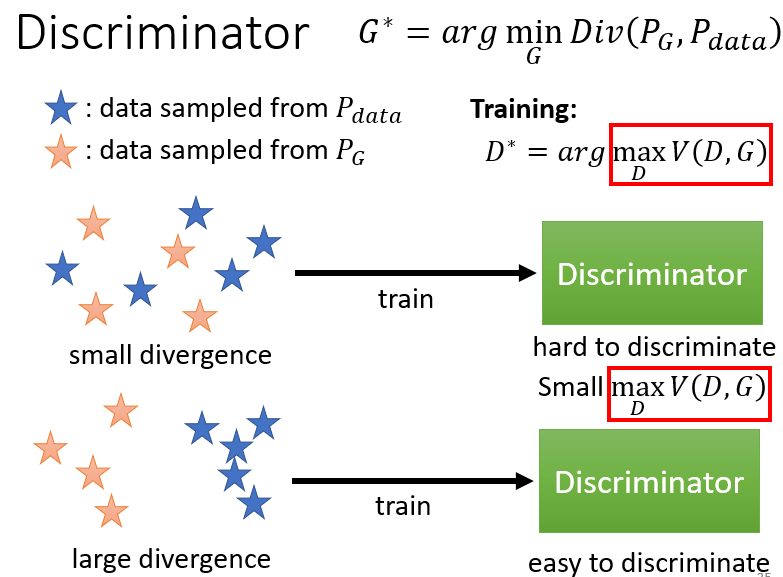
- 跟 很像,它們差距沒有很大時,discriminator 就是在訓練一個 binary classifier,這個問題很難,所以在解此 optimization problem 就沒有辦法讓二元分類器訓練任務的損失函數(cross entropy)很小,也就是沒有辦法讓 objective 的值 非常大 ⇒ 小的 divergence,對應 的 maximum 的值就比較小
- 跟 很不像,divergence 值很大,此時這個二元分類器就可以很輕易地分開,訓練的損失函數很小,也就是目標函數 的值很大 ⇒ 大的 divergence,對應 的Maximum 的值就比較大
結論:
要 minimize 的是 跟 的 divergence,但要計算 divergence 很困難,所以藉由 discriminator 來找出一個 objective function 要去 maximize,但發現要 maximize 的 跟 JS divergence 有關聯,所以直接把 替換成
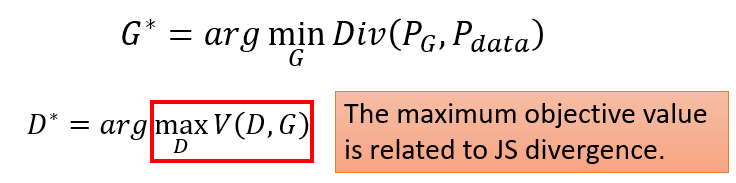

不同的 obejctive function 與 divergence 之間的對應關係

4. Tips for training GAN
4.1 JS Divergence 特性
- 的分布和 的分佈重疊的部分非常小

跟 它們都是要產生圖片的。圖片是高維空間裡面的一個非常狹窄的低維的 manifold。高維空間中隨便 Sample 一個點都不是圖片,只有非常小的範圍 sample 出來會是圖片。再者 跟 都是 low dimensional 的 manifold,除非剛好重合,不然它們相交的範圍幾乎是可以忽略的
* Manifolds 是可以局部歐幾里德空間化的一個拓撲空間,是歐幾里德空間中的曲線、曲面等概念的推廣
- 基於 sample 的 divergence 衡量具有局限性 ⇒ 難以採樣到“重疊的點”
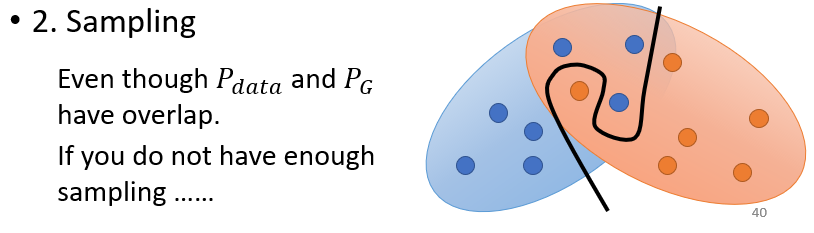
由於我們無法得知 與 的真實情況,只能通過 sample 來進行推斷。對於 discriminator 來說,如果 Sample 的點不夠多、不夠密,就算這兩個 distribution 實際上有重疊,也無法判斷出來
4.1.1 結合 JS Divergence

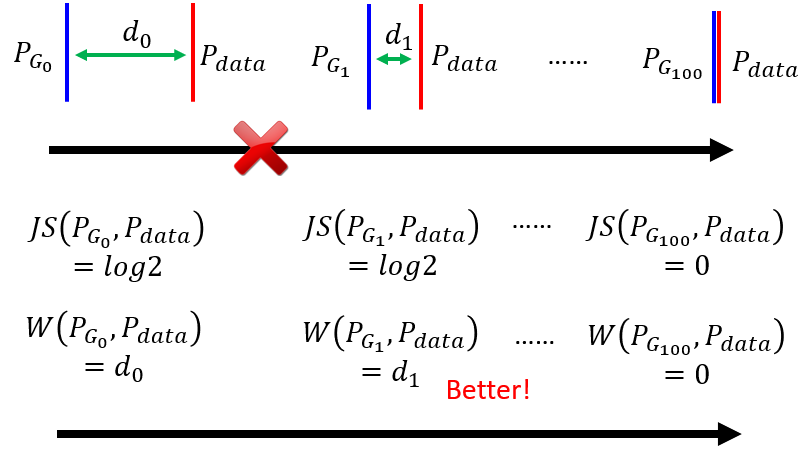
JS Divergence 的特性是兩個沒有重疊的分布 JS Divergence 算出來的值恆為 Log2,無法衡量這類(沒有重疊的)分布之間的關係
4.2 Wasserstein distance(WGAN)
使用 Wasserstein distance 代替 JS Divergence。“推土”距離的最小值 ⇒ 必須窮舉/優化問題

用從 P 移到 Q 的位置的距離衡量兩個分布 P 與 Q 之間的差異。Wasserstein Distance 的作用能夠分辨出沒有重疊 distribution 的差距,實現兩個分布從毫不相關到逐漸相關
4.2.1 Wasserstein 的計算
目標是要 maximize 這個 objective function:
如果是從 來的,計算 的期望值,希望越大越好
如果是從 來的,計算 的期望值,但是前面乘上一個負號,所以希望越小越好

必須要是一個足夠平滑的 function,不可以是變動很劇烈的 function。即使兩個分布沒有重疊時,也不會出現“過於劇烈”的 ,可以保證收斂性 ⇒ 避免了 JS Divergence 出現的問題
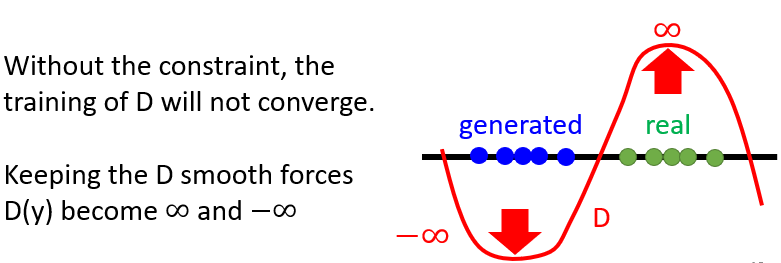
問題:要如何讓 符合 的限制?
方法:
- 限制參數大小
但並不一定能夠讓 discriminator 符合 1-Lipschitz Function

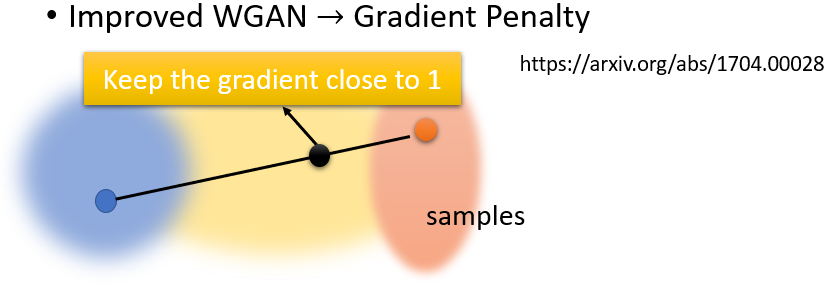
- Gradient Penalty
在 real data 取一個 sample,fake data 取一個 sample,兩點連線中間再取一個 sample,要求這個點它的 gradient 要接近 1
- Spectral Normalization
可以保證符合 1-Lipschitz,可參考:Spectral Normalization for Generative Adversarial Networks
4.3 Train GAN 的困難之處
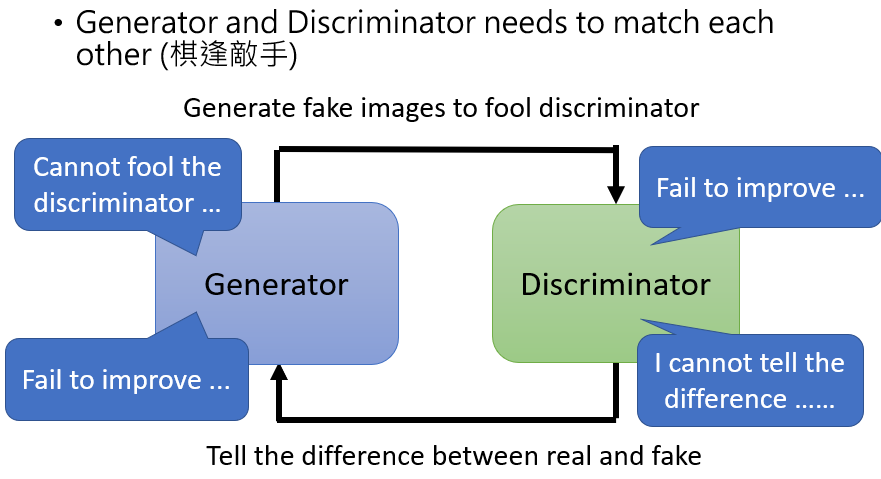
generator 跟 discriminator 是互相砥礪才能互相成長,只要其中一者發生什麼問題停止訓練,另外一者就會跟著停下訓練,如果有一次loss沒有下降,那整個訓練過程都有可能出現問題。所以需要保證二者的 loss 在這一過程中不斷下降
4.4 More Tips
5. GAN for sequence generation
利用 GAN 來生成文字,decoder 就是 generator,目標是騙過 discriminator
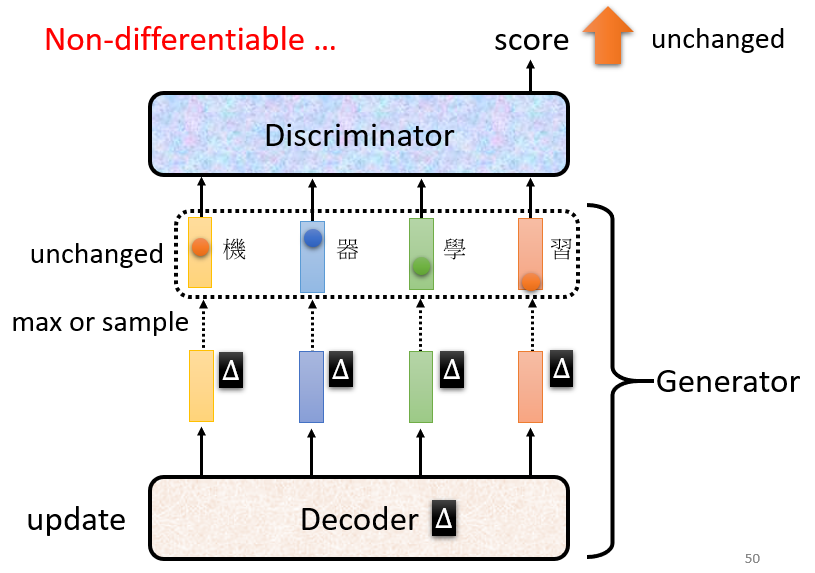
問題:
要用 gradient descent 去訓練 decoder 讓 discriminator 輸出分數越大越好,但會發現做不到
原因:
由於取了max,這一運算使得 discriminator 的 score 對 decoder 參數不可微分,也就不能做 gradient descent
解決:
不能用 gradient descent 的問題,可以使用 RL 硬訓練或是使用 pretrain
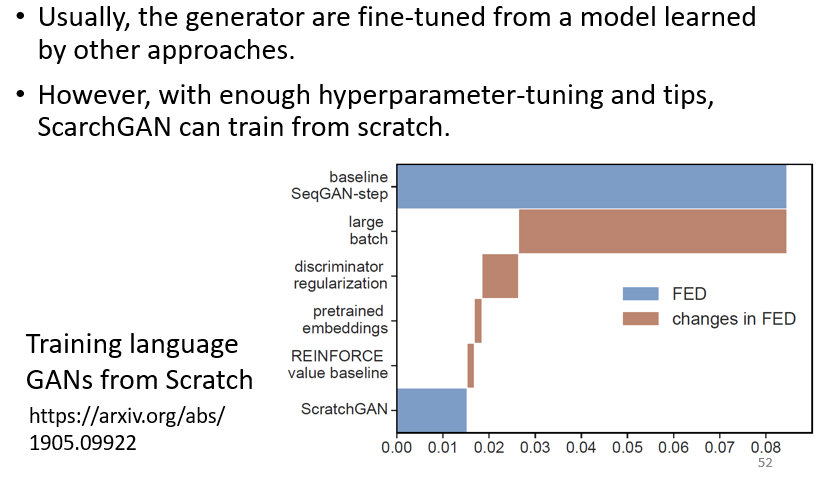
5.1 ScratchGAN:Training language GANs from Scratch
直接從隨機的初始化參數開始訓練 generator,然後讓 generator 可以產生文字,該模型最關鍵的就是爆調超參數跟一大堆的 tips
6. Learn More

supervised learning 訓練生成式模型:
每一個圖片配一個從 gaussian distribution sample 出來的 vector,訓練一個 network,輸入一個 vector 輸出就是它對應的圖片,把對應的圖片當做訓練目標訓練
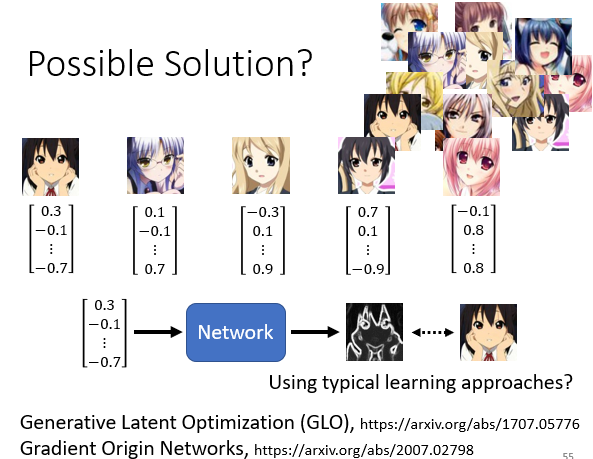
Generative Latent Optimization (GLO):Optimizing the Latent Space of Generative Networks
Gradient Origin Networks:Gradient Origin Networks
7. Evaluation of Generation
- 直覺的方法:人眼來看,但不客觀且不穩定
- 自動化方法:借助影像辨識系統
7.1 Quality(對單張圖片)
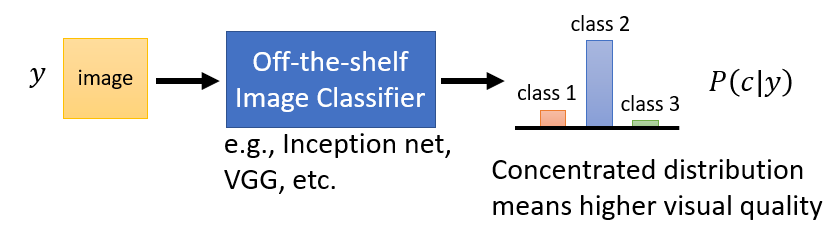
將圖片輸入影像辨識系統,若機率分布越集中,說明產生的圖片能夠被影像分類系統很肯定地分辨出來,代表產生的圖片品質越好;反之若機率分布越平坦,代表產生的圖片品質低
7.2 Diversity(對所有圖片)
7.2.1 Mode Collapse
generator 輸出的分布局限在很小的範圍內

7.2.2 Mode Dropping
訓練輸出的分布範圍較大,但沒有完全覆蓋真實數據分布(多樣性減小)

7.2.3 評估 diversity
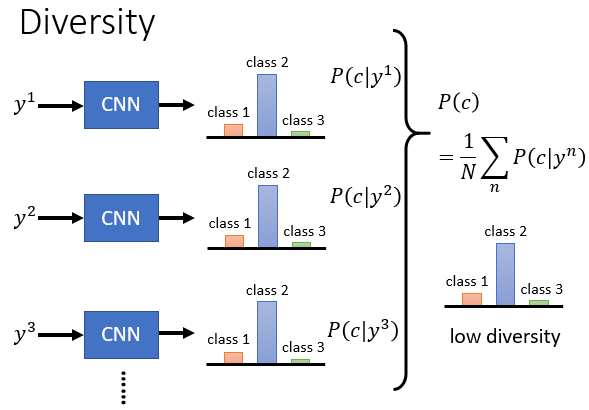
把影像辨識系統對所有生成結果的輸出平均起來
平均分布集中,表示多樣性低
平均分布均勻,表示多樣性高
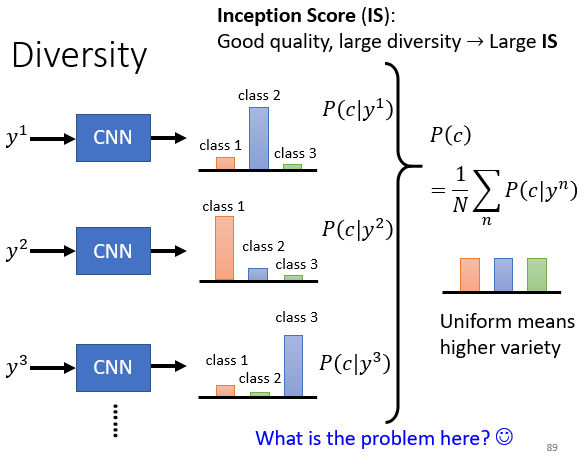
Inception Score(IS)
⇒ 基於 CNN 的 Inception network。將生成結果放進 Inception network,通過輸出的分布結果來衡量。如果 quality 高且 diversity 又大,那麼 Inception Score 就會比較大
7.3 Fréchet Inception Distance(FID)
現今較常用的評估方法。將圖片送入 Inception Network,取 softmax 之前的 hidden layer 輸出的向量,來代表這張圖片,利用這個向量來衡量兩個分布之間的關係
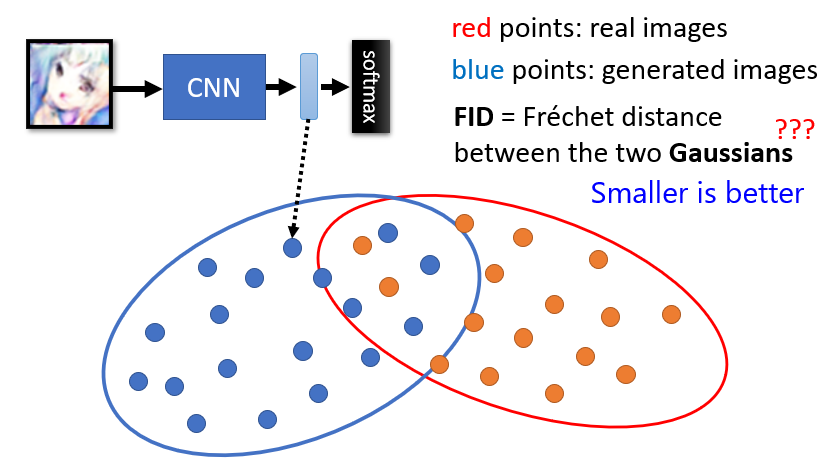
假設真實數據和生成數據的兩個分布,都是從高斯分布中抽樣得到的,計算兩個高斯分布之間的 Fréchet Distance,越小代表分布越接近,圖片品質越高
問題:
- 將任意分布都視為高斯分布會有問題
- 因計算 FID 需要大量的採樣,所以計算量大
7.4 不希望 GAN 有記憶性
訓練了一個 generator,它產生出來的 data 跟真實資料一模一樣,但這實際上並無意義


或是只學會了左右反轉,也沒有意義

7.5 更多 Evaluation 方法

8. Conditional Generation
在 2.1 Unconditional Generation 不考慮 ,而 Conditional Generation 則將 考慮進去
8.1 Case 1:Text-to-Image
操控 generator 的輸出,給它 condition ,再從一個簡單分布中抽樣 ,讓 generator 根據 和 來產生圖片
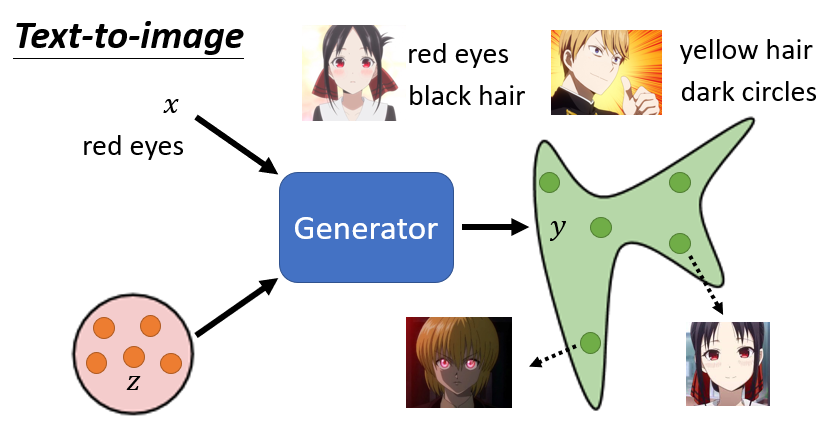
8.1.1 如何訓練 Discriminator
discriminator 不再只輸入圖片 ,它還要輸入 condition 。一方面圖片要好,另外一方面圖片跟文字的敘述必須要相配,discriminator 才會給高分
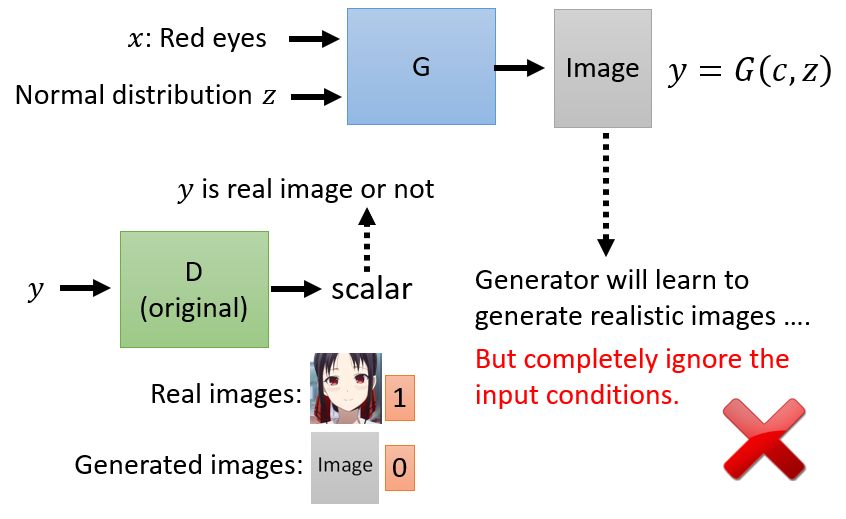
需要有文字敘述和影像的成對資料來訓練 discriminator,所以一般而言 conditional GAN 要訓練都必須是要有有標註且成對的資料。匹配上就得高分,匹配不上就得低分
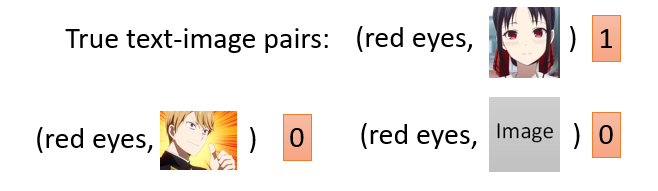
8.2 Case 2:Image Translation(pix2pix)
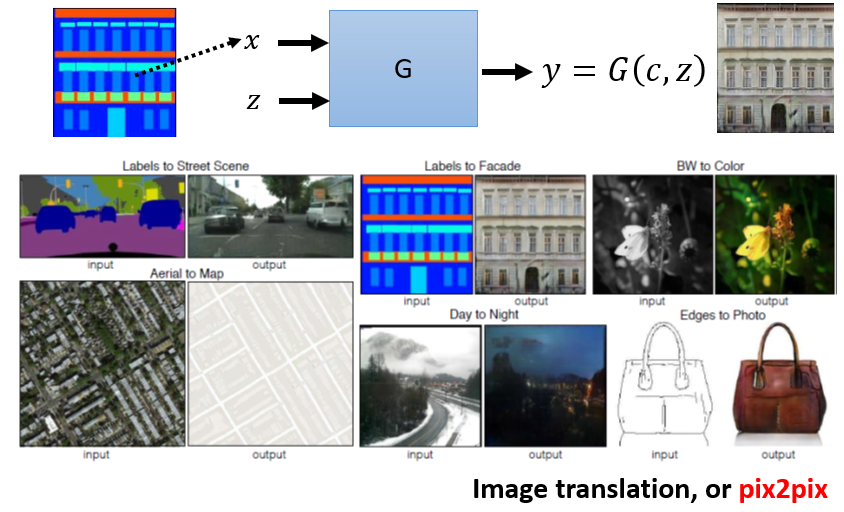

單純利用 supervised learning 訓練會造成輸出模糊,因為同樣的輸入可能對應到不一樣的輸出(同一個轉角,小精靈可能左轉也可能右轉,最後學到的就是同時左轉跟右轉)
單純利用 GAN 產生出來的圖片雖比較真實,但是問題是它的想像力過度豐富,出現不該出現的東西
⇒ 結合 GAN 跟 supervised learning,測試上就可以有比較好的結果
8.3 Case 3:Sound-to-Image
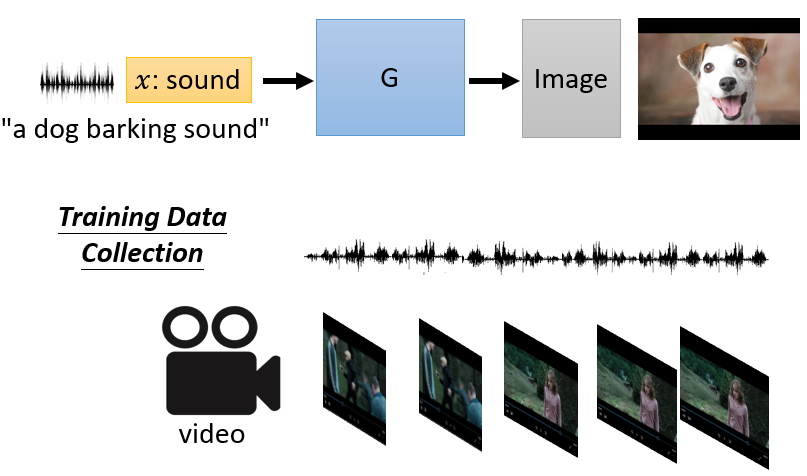
8.4 Case 4:產生會動的圖像

9. Learning from Unpaired Data
把 GAN 應用在 unsupervised learning 上,因為有時無法蒐集到成對的資料(稱為 unlabeled data)
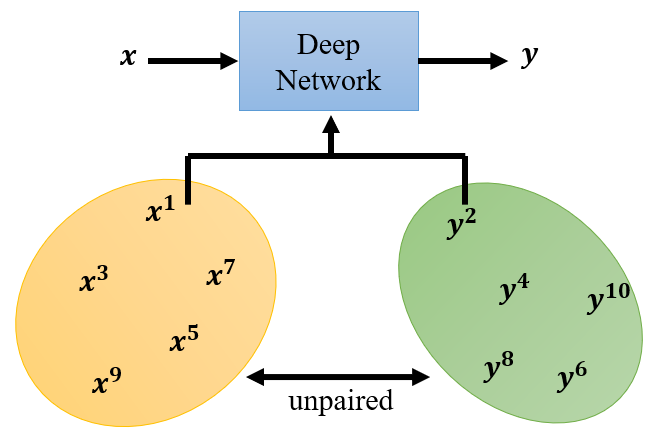
9.1 影像風格轉換
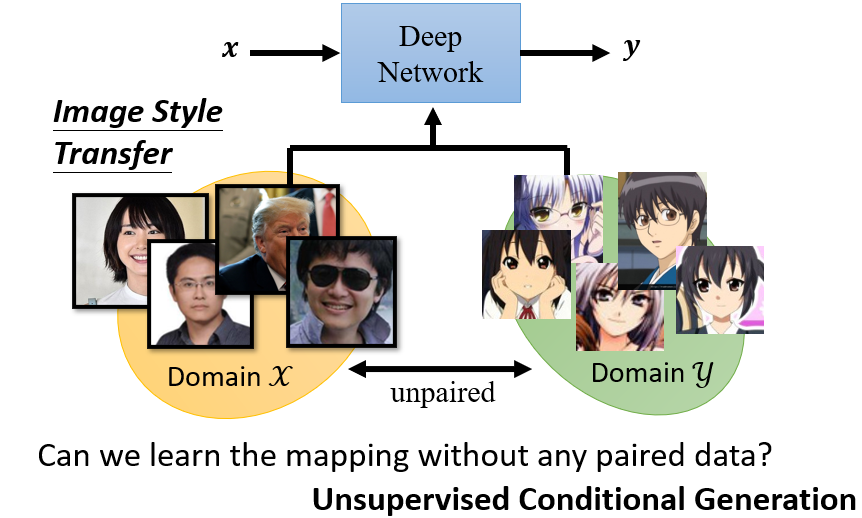
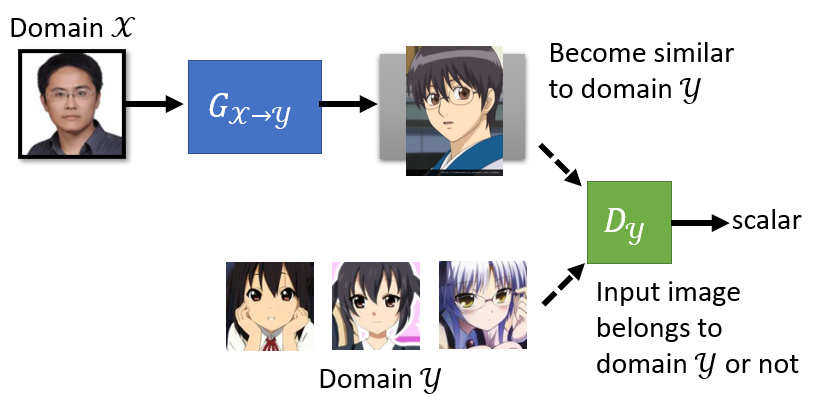
套用原來的方法,但這邊將 sample 的對象從一個 simple distribution 改為 domain ,而 discriminater 利用 domain 中的圖像做訓練,確保輸出圖片屬於 domain
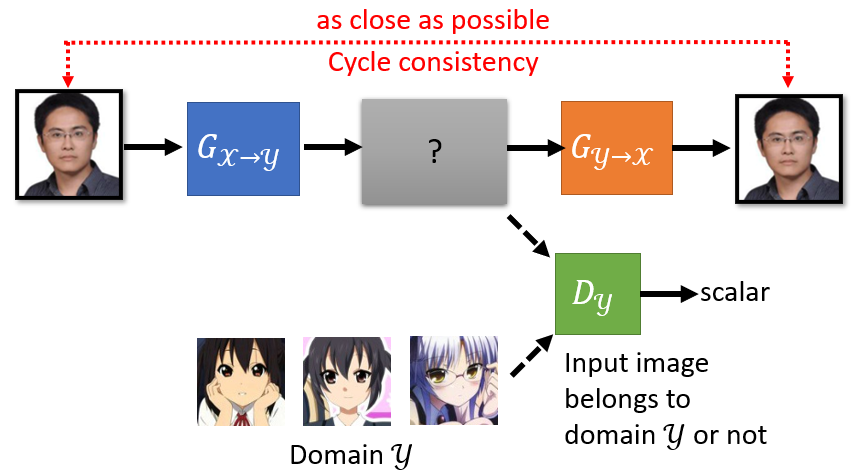
9.2 Cycle GAN
有一個循環,從 到 在從 回到 ,是一個 cycle 所以叫做 Cycle GAN。利用這種架構,強迫 generator 輸出的 domain 圖片跟輸入的 domain 圖片有一些關係
增加第二個 generator,第一個 generator 的工作是把 轉成 ,第二個 generator 的工作是要把 還原回原來的 ,而 discriminator 的工作仍然是要看第一個 generator 的輸出像不像是 domain 的圖
Cycle GAN 可以是雙向的,給橘色的 generator domain 的圖片,讓它產生 domain 的圖片,然後輸入到藍色的 generator 還原回原來 domain 的圖片
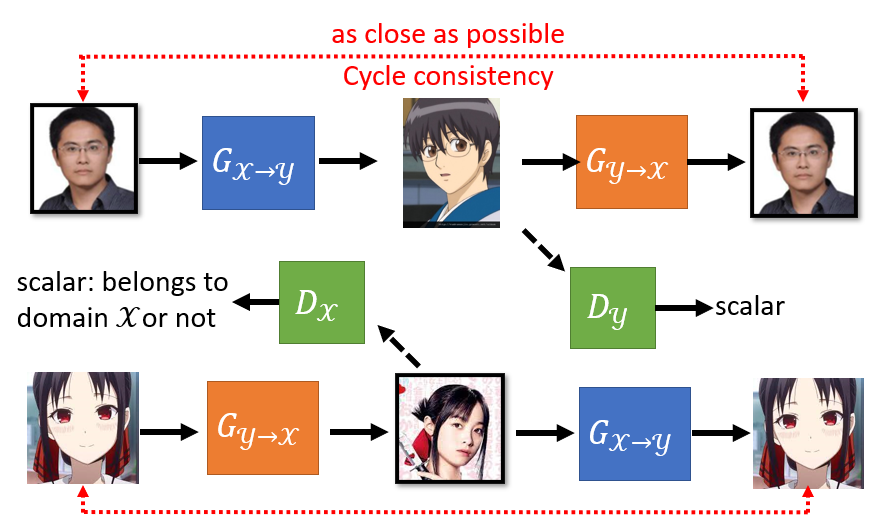
9.3 More style-transfer GAN
Learning to Discover Cross-Domain Relations with Generative Adversarial Networks(Disco GAN)
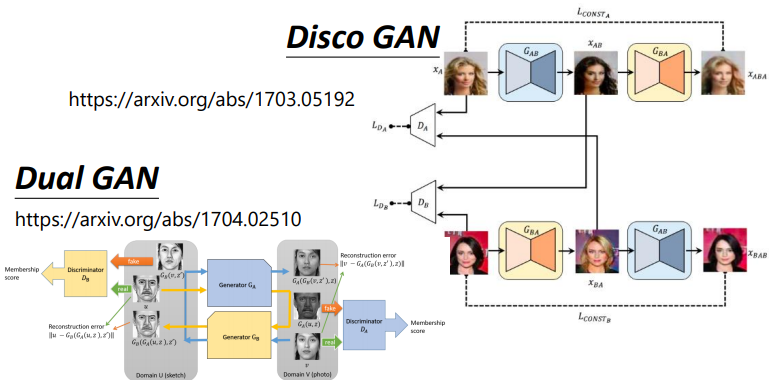
DualGAN: Unsupervised Dual Learning for Image-to-Image Translation(Dual GAN)
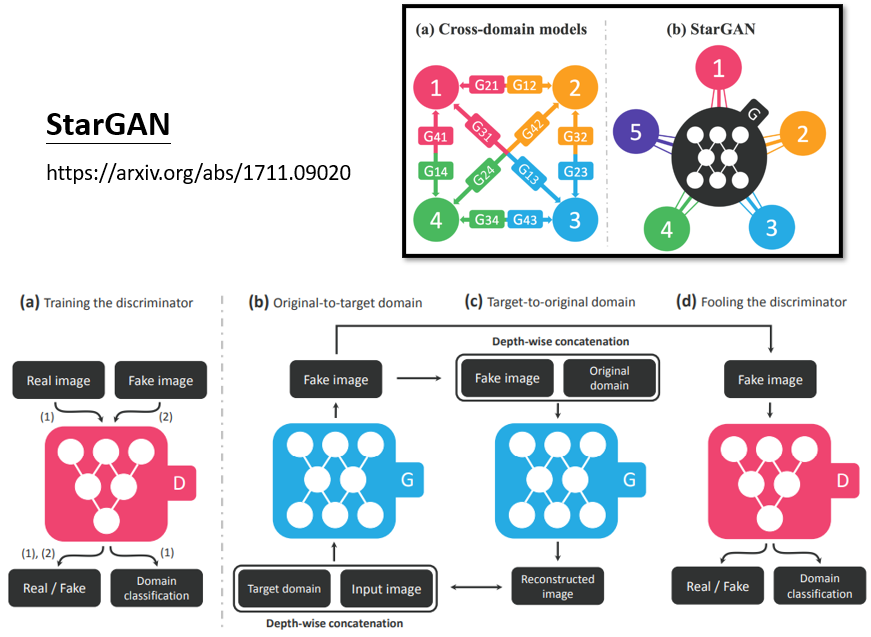
StarGAN: Unified Generative Adversarial Networks for Multi-Domain Image-to-Image Translation
(StarGAN,多種風格間做轉換)
9.4 More Cases